Elephant GPS Collars Data
Elephant GPS Collars Data#
The Danau Girang Field Centre (DGFC) https://www.dgfc.life/home/ provided us with the collars data for elephants. Collars weighing approximately 14 kg each were officially placed around the elephants’ necks to record numerous metrics every two hours, including time, geolocation, and temperature. In this study, we modelled twenty-two adult Asian elephants (Elephas maximus), fourteen females and eight males. The collars were created by Africa Wildlife Tracking and fitted ethically by a team of researchers, trackers, and a wildlife vet. Each collar had a Global Positioning System (GPS) receiver and a Very High Frequency (VHF) transmitter. At predetermined intervals, the GPS uploaded each individual’s geographical location information to the Globaltrack server, which could be officially obtained from the Globaltrack website (http://www.globaltrack.com). The built-in VHF transmitter aided in retrieving collars that had come off naturally or in locating an individual when additional monitoring was required. The observations in those datasets cover the period range between 2012 to 2018. We refrain from publishing the datasets used in this study because they could be misused to locate an endangered species at risk of poaching.
!pip install rdflib
from google.colab import files
import pandas as pd
import csv
from rdflib import Graph, Namespace, URIRef, Literal
from rdflib.namespace import RDF, XSD
# Prompt for file upload
uploaded = files.upload()
# Read the uploaded CSV file into a pandas DataFrame
for filename in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=filename, length=len(uploaded[filename])))
df = pd.read_csv(filename)
# Define namespaces
FOO = Namespace("https://w3id.org/def/foo#")
SOSA = Namespace("http://www.w3.org/ns/sosa/")
GEO = Namespace("http://www.w3.org/2003/01/geo/wgs84_pos#")
# Create a new graph
g = Graph()
# Bind namespaces
g.bind("foo", FOO)
g.bind("sosa", SOSA)
g.bind("geo", GEO)
# Path to your CSV file
csv_file_path = "Jasmin.csv" # Adjust the path accordingly, Jasmin is an elephant.
# Read and process data
with open(csv_file_path, newline='', encoding='utf-8-sig') as csvfile:
reader = csv.DictReader(csvfile, delimiter=',')
# Print headers for debugging
print("Headers:", reader.fieldnames)
for row in reader:
identifier = row.get('ID', '').strip()
local_date = row.get('LocalDate', '').strip()
local_time = row.get('LocalTime', '').strip()
gmt_date = row.get('GMTDate', '').strip()
gmt_time = row.get('GMTTime', '').strip()
lat = row.get('lat', '').strip()
long = row.get('long', '').strip()
temperature = row.get('Temperature', '').strip()
speed = row.get('Speed', '').strip()
direction = row.get('Direction', '').strip()
altitude = row.get('Altitude', '').strip()
cov = row.get('Cov', '').strip()
hdop = row.get('HDOP', '').strip()
distance = row.get('Distance', '').strip()
count = row.get('Count', '').strip()
# Create observation URI
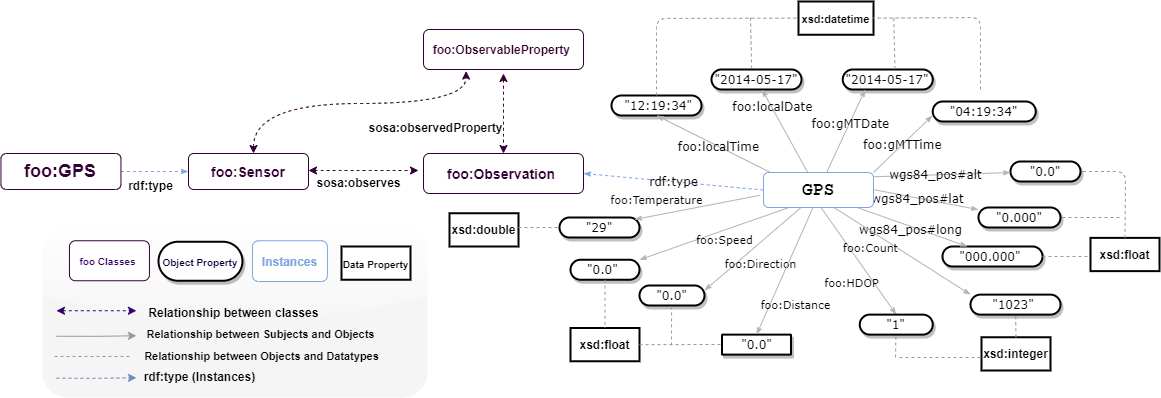
observation = URIRef(f"https://w3id.org/def/foo#{identifier}")
g.add((observation, RDF.type, FOO.gPSObservation))
g.add((observation, FOO.id, Literal(identifier, datatype=XSD.string)))
g.add((observation, FOO.madeBySensor, FOO.jasminGPS)) # Link sensor to observation
g.add((observation, FOO.hasFeatureOfInterest, FOO.jasmin))
# Add observation properties
g.add((observation, FOO.localDate, Literal(local_date, datatype=XSD.date)))
g.add((observation, FOO.localTime, Literal(local_time, datatype=XSD.time)))
g.add((observation, FOO.gMTDate, Literal(gmt_date, datatype=XSD.date)))
g.add((observation, FOO.gMTTime, Literal(gmt_time, datatype=XSD.time)))
g.add((observation, GEO.latitude, Literal(lat, datatype=XSD.double)))
g.add((observation, GEO.longitude, Literal(long, datatype=XSD.double)))
# Add observable properties if available
if temperature:
g.add((observation, FOO.temperature, Literal(temperature, datatype=XSD.double)))
if speed:
g.add((observation, FOO.speed, Literal(speed, datatype=XSD.double)))
if direction:
g.add((observation, FOO.direction, Literal(direction, datatype=XSD.integer)))
if altitude:
g.add((observation, FOO.altitude, Literal(altitude, datatype=XSD.string)))
if cov:
g.add((observation, FOO.cov, Literal(cov, datatype=XSD.double)))
if hdop:
g.add((observation, FOO.hDOP, Literal(hdop, datatype=XSD.double)))
if distance:
g.add((observation, FOO.distance, Literal(distance, datatype=XSD.double)))
if count:
g.add((observation, FOO.cOUNT, Literal(count, datatype=XSD.integer)))
# Serialize the graph to a file
output_file = "sensor_knowledge_graph.ttl"
g.serialize(destination=output_file, format="turtle")
print(f"Knowledge graph has been serialized to {output_file}")
# Download the file
files.download(output_file)
```python
# # adding serialized data to stardog
# conn_details = {
# 'endpoint': 'http://localhost:5820',
# 'username': 'admin',
# 'password': 'admin'
# }
# with stardog.Admin(**conn_details) as admin:
# Jasmin = admin.new_database('Jasmin')
# conn = stardog.Connection('Jasmin', **conn_details)
# conn.begin()
# conn.add(
# stardog.content.File('Jasmin.rdf', stardog.content_types.TURTLE),
# )
# conn.commit()